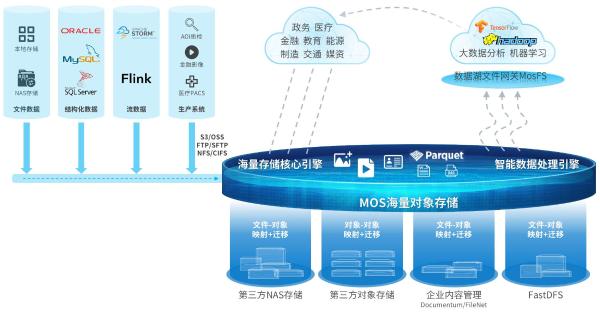
在當今以數據和智能為核心驅動力的時代,數據存儲與管理技術正經歷著深刻的范式轉變。杉巖數據首席技術官邱尚高先生近期指出,隨著人工智能(AI)的深度融合與數據湖架構的廣泛采納,對象存儲已遠非簡單的數據存放倉庫,其角色正從被動存儲向主動、智能的數據服務基石演進。
一、AI與數據湖:驅動存儲需求變革的雙引擎
人工智能,特別是大規模機器學習與深度學習,對數據提出了前所未有的要求:海量的非結構化數據(如圖像、視頻、文本)、高吞吐的訪問性能、以及跨地域、跨集群的高效數據流轉。與此數據湖作為集中存儲企業各種原始數據的大型存儲庫,其核心理念是打破數據孤島,支持多樣化的分析工作負載。這兩大趨勢共同作用,對底層存儲系統的可擴展性、經濟性、協議兼容性及元數據管理能力構成了嚴峻考驗。傳統的存儲方案往往難以兼顧規模、成本與靈活性。
二、對象存儲:數據湖的理想底座
對象存儲憑借其近乎無限的橫向擴展能力、基于策略的自動化數據生命周期管理、以及通過標準S3等API實現的廣泛生態兼容性,天然契合數據湖的建設需求。它能夠以相對低廉的成本,高效地存儲和管理EB級的海量非結構化數據,為上層的數據分析、AI訓練提供統一、可靠的數據源。邱尚高強調,對象存儲已成為構建現代數據湖事實上的標準存儲層。
三、不止于存儲:向智能數據服務演進
邱尚高認為,在AI+數據湖的時代,對象存儲的價值絕不應止步于“存得住”和“取得出”。其發展的關鍵方向在于“用得好”,即演變為智能的數據服務平臺。這主要體現在以下幾個方面:
- 性能與智能加速:針對AI訓練等數據密集型場景,對象存儲需要通過緩存加速、與計算框架緊耦合、支持GPU Direct Storage等技術,顯著降低數據訪問延遲,提升整體訓練效率。智能的數據預取、分層策略可以進一步優化數據流轉。
- 豐富的元數據與標簽化:強大的自定義元數據能力,使得對象存儲能夠為每個數據對象打上豐富的語義標簽。結合AI對元數據進行自動分析、分類和標注,可以極大提升數據治理水平和發現效率,讓數據更“易理解”、更“可搜索”。
- 內置數據處理能力:下一代對象存儲開始探索將部分計算邏輯“下推”到存儲層,例如支持在存儲側直接進行圖片轉碼、視頻截圖、數據過濾等輕量級處理(類似于S3 Select/Object Lambda理念),減少不必要的數據移動,實現“存算融合”。
- 數據安全與合規智能化:利用AI能力,對象存儲可以更智能地識別敏感數據,實現自動化的分類分級、加密、脫敏和訪問控制,并滿足日益嚴格的數據合規性要求。
- 統一數據視圖與流動:作為數據湖的核心,對象存儲需要與HDFS、數據庫、數據倉庫等系統無縫協同,提供統一命名空間,并智能化地調度數據在不同存儲層級(熱、溫、冷)及不同系統間的流動,支撐混合云、多云環境下的數據管理。
四、展望:構建以數據為中心的基礎設施
邱尚高道,未來的競爭是數據的競爭,更是數據利用效率的競爭。對象存儲作為承載企業核心數據資產的基石,其發展必須與上層應用(尤其是AI)的需求同頻共振。杉巖數據等廠商正在推動對象存儲向更智能、更融合、更服務化的方向發展,目標是將存儲基礎設施從成本中心轉變為賦能業務創新的數據服務中心。在AI與數據湖的雙重浪潮下,對象存儲的旅程,才剛剛駛向更廣闊的深海。